
How Generative AI Works: Context Windows, Semantic Search, Fine-Tuning & Inference Basics
GenAI Fundamentals Explained: Tokens, Embeddings, Prompts & Model Behavior Made Simple


The Customer Support Agent Who Solved 11,000 Queries Overnight
At 2:13 AM, while most of the support team slept, an e-commerce company in Mumbai quietly processed over 11,000 customer requests without a single human agent online.
Refunds were explained.
Delivery delays were clarified.
Products were recommended.
Conversations flowed naturally across English, Hindi, and regional languages.
But by morning, executives noticed something troubling.
A few customers had received completely fabricated return policies.
One chatbot confidently invented warranty terms that never existed.
Another generated inaccurate medical advice for a wellness product.
The system sounded intelligent.
But intelligence without control had become a business risk.
That night revealed one of the most important truths of the Generative AI era:
Using GenAI successfully is not just about asking questions.
It is about understanding the architecture behind how AI thinks, predicts, retrieves, remembers, and generates responses.
And that foundation begins with the core mechanics of Generative AI itself.
The Hidden Infrastructure Behind Generative AI
To most users, Generative AI feels almost magical.
A question goes in.
An intelligent answer comes out.
But beneath every AI-generated response exists a sophisticated system involving:
tokens
context windows
embeddings
inference engines
semantic search
prompts
probability calculations
The quality of AI outputs depends heavily on how these components interact.
Businesses adopting GenAI without understanding these mechanics often encounter:
hallucinations
inconsistent outputs
rising operational costs
context failures
unreliable automation
Understanding GenAI fundamentals is now becoming as essential as understanding the internet was two decades ago.
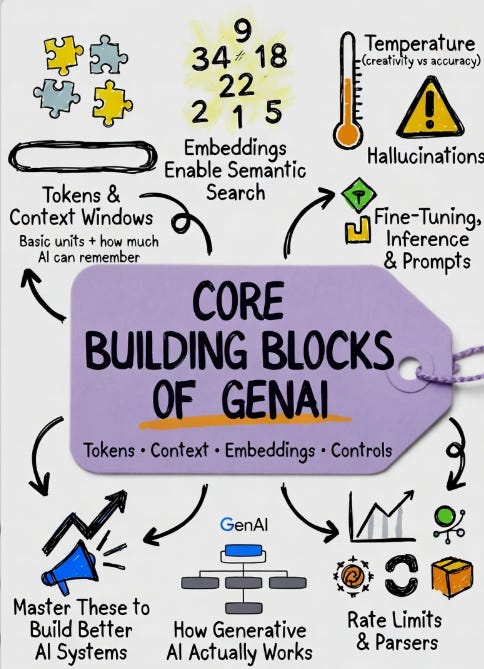
Tokens, Context Window, Rate Limits & Parsers
Tokens — The Language Units of AI
AI models do not process words exactly the way humans do.
They process tokens.
A token may represent:
a word
part of a word
punctuation
symbols
spaces
For example:
Artificial Intelligence may be broken into multiple tokens internally.
Every interaction with a GenAI model consumes tokens.
This directly impacts:
cost
speed
memory usage
processing limits
In enterprise environments processing millions of interactions daily, token optimization becomes a major operational concern.
Context Window — AI’s Working Memory
The context window defines how much information the AI model can remember during a conversation or task.
A larger context window allows models to:
analyze long documents
maintain conversation continuity
process extensive instructions
understand historical interactions
But context is limited.
Once the window fills, earlier information may be forgotten or compressed.
This is why some AI conversations suddenly lose track of earlier details.
For businesses, managing context effectively is critical for:
customer support
legal analysis
medical documentation
research workflows
Rate Limits — The Operational Boundaries
AI systems cannot process unlimited requests simultaneously.
Platforms impose rate limits controlling:
requests per minute
token usage
concurrent processing
Without proper infrastructure planning, businesses may experience:
API failures
delayed responses
system bottlenecks
As AI adoption grows, scalability becomes both a technical and financial challenge.
Parsers — Structuring AI Outputs
AI responses are often unstructured.
Parsers convert generated outputs into structured formats usable by software systems.
For example:
extracting order IDs
identifying customer names
converting AI text into database entries
formatting outputs into JSON or workflows
Parsers bridge the gap between conversational AI and operational systems.
Embeddings, Cosine Similarity & Semantic Search
Traditional search systems rely heavily on exact keywords.
Generative AI introduced a fundamentally different approach:
understanding meaning instead of matching words.
Embeddings — Turning Meaning Into Mathematics
Embeddings convert text, images, or data into numerical vector representations.
These vectors capture semantic meaning.
For example:
doctor
physician
medical specialist
may produce closely related embeddings even if the exact words differ.
This allows AI systems to understand conceptual similarity.
Cosine Similarity — Measuring Meaning Distance
Once embeddings are created, systems use cosine similarity to measure how closely two vectors relate.
Higher similarity means stronger conceptual connection.
This enables:
intelligent recommendations
document retrieval
AI memory systems
contextual understanding
Modern AI applications depend heavily on these mathematical relationships.
Semantic Search — Search That Understands Intent
Semantic search retrieves information based on meaning rather than literal keywords.
A customer searching:
How do I stop late deliveries?
may retrieve documents related to:
shipping delays
logistics optimization
delivery escalation policies
even if those exact words never appear.
This dramatically improves:
enterprise knowledge systems
customer support
research productivity
AI assistants
Temperature Control & Hallucinations
One of the most misunderstood aspects of GenAI is output variability.
AI responses are influenced by probability.
That probability can be adjusted using temperature settings.
Temperature Control
Temperature determines how creative or predictable AI responses become.
Low temperature:
more factual
more deterministic
more stable outputs
High temperature:
more creative
more diverse
less predictable
Businesses often use lower temperatures for:
legal
healthcare
finance
operational workflows
Higher temperatures may be useful for:
storytelling
brainstorming
creative marketing
Hallucinations — When AI Invents Information
Hallucinations occur when AI generates inaccurate or fabricated outputs presented confidently as facts.
This happens because AI predicts likely sequences rather than verifying truth.
Hallucinations remain one of the greatest enterprise risks in Generative AI adoption.
In sensitive industries, hallucinations can lead to:
legal exposure
misinformation
compliance failures
customer distrust
Reducing hallucinations requires:
grounding systems with verified data
retrieval mechanisms
prompt engineering
human oversight
fine-tuning strategies
Model Fine-Tuning Fundamentals
Foundational AI models are trained on broad internet-scale datasets.
But businesses often require specialized intelligence.
Fine-tuning adapts general models for domain-specific tasks.
For example:
healthcare terminology
financial compliance
restaurant ordering workflows
legal documentation
customer support policies
Fine-tuning improves:
accuracy
contextual relevance
industry alignment
response consistency
This enables organizations to create AI systems tailored to their operational environments.
Model Inferencing
Training a model is only the beginning.
Inference is the real-time process where the trained AI generates outputs based on user input.
Every chatbot response, recommendation, or generated image is produced during inference.
Inference performance affects:
response speed
scalability
infrastructure costs
user experience
As AI adoption expands globally, inference optimization is becoming one of the most critical areas in enterprise AI architecture.
System Prompts & Prompt Templates
Generative AI systems behave based on instructions.
The quality of those instructions heavily shapes the output.
System Prompts
System prompts define the AI’s overall behavior, personality, rules, and boundaries.
For example:
tone of communication
safety restrictions
formatting requirements
role specialization
A customer service AI and a medical assistant AI may use entirely different system prompts despite using the same foundational model.
Prompt Templates
Prompt templates standardize AI interactions for consistency and scalability.
Businesses use templates to:
automate workflows
maintain brand voice
improve reliability
reduce prompt variability
For example:
customer support workflows
sales outreach
report generation
product recommendations
Prompt engineering is rapidly becoming a core business capability.
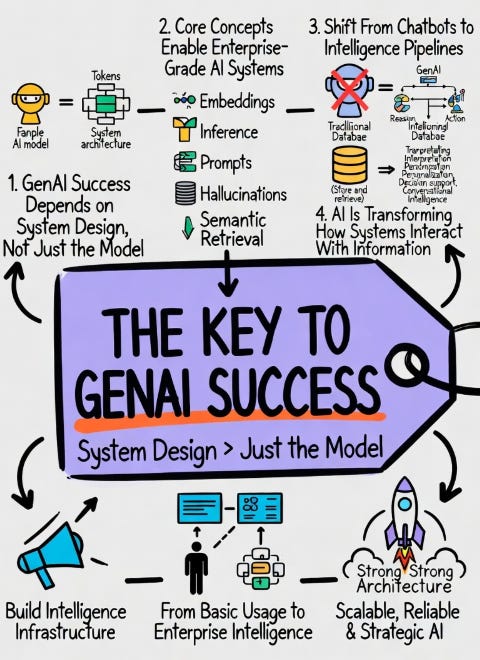
Why These Fundamentals Matter
Many organizations rush into Generative AI believing the technology alone guarantees intelligence.
But GenAI systems are only as effective as the architecture surrounding them.
Understanding:
tokens
embeddings
inference
prompts
hallucinations
semantic retrieval
allows businesses to move from experimental AI usage to enterprise-grade intelligent systems.
The companies succeeding with AI are not simply using chatbots.
They are engineering intelligence pipelines.
The Shift From Information Retrieval to Intelligent Interaction
For decades, software systems focused on storing and retrieving information.
Generative AI changes that relationship entirely.
Modern AI systems can:
interpret meaning
generate responses
retrieve context
adapt communication
personalize interactions
assist decision-making
This is not merely a software upgrade.
It is the emergence of conversational intelligence infrastructure.
And as businesses integrate GenAI into every operational layer, understanding these fundamentals will become as essential as understanding cloud computing or digital platforms in previous technological eras.
Do you have any Queries Comment Below - AI for professionals @mom AI Book
Hope you enjoyed , If you think this is useful , please do share your thoughts.
OR
We will add you under Paid Membership for one year,It will be activated in a day.